 ENG
ENG- Branchen
- Finanzen
Nearshore-Softwareentwicklung für den Finanzsektor – sicher, skalierbar und Compliance-gerechte Lösungen für Banking, Zahlungsverkehr und APIs.
- Einzelhandel
Softwareentwicklung für den Einzelhandel – E-Commerce, Kassensysteme, Logistik und KI-gestützte Personalisierung durch unsere Nearshore-Engineering-Teams.
- Verarbeitende Industrie
Nearshore-Softwareentwicklung für die Industrie – ERP-Systeme, IoT-Plattformen und Automatisierungstools zur Optimierung industrieller Abläufe.
- Finanzen
- Was wir tun
- Services
- Technologien
- Kooperationsmodelle
Kooperationsmodelle passend zu Ihren Bedürfnissen: Komplette Nearshoring Teams, deutschsprachige Experten vor Ort mit Nearshoring-Teams oder gemischte Teams mit unseren Partnern.
- Arbeitsweise
Durch enge Zusammenarbeit mit Ihrem Unternehmen schaffen wir maßgeschneiderte Lösungen, die auf Ihre Anforderungen abgestimmt sind und zu nachhaltigen Ergebnissen führen.
- Über uns
- Wer wir sind
Wir sind ein Full-Service Nearshoring-Anbieter für digitale Softwareprodukte, ein perfekter Partner mit deutschsprachigen Experten vor Ort, Ihre Business-Anforderungen stets im Blick
- Unser Team
Das ProductDock Team ist mit modernen Technologien und Tools vertraut und setzt seit 15 Jahren zusammen mit namhaften Firmen erfolgreiche Projekte um.
- Wozu Nearshoring
Wir kombinieren Nearshore- und Fachwissen vor Ort, um Sie während Ihrer gesamten digitalen Produktreise optimal zu unterstützen. Lassen Sie uns Ihr Business gemeinsam auf das nächste digitale Level anheben.
- Wer wir sind
- Unser Leistungen
- Karriere
- Arbeiten bei ProductDock
Unser Fokus liegt auf der Förderung von Teamarbeit, Kreativität und Empowerment innerhalb unseres Teams von über 120 talentierten Tech-Experten.
- Offene Stellen
Begeistert es dich, an spannenden Projekten mitzuwirken und zu sehen, wie dein Einsatz zu erfolgreichen Ergebnissen führt? Dann bist du bei uns richtig.
- Info Guide für Kandidaten
Wie suchen wir unsere Crew-Mitglieder aus? Wir sehen dich als Teil unserer Crew und erklären gerne unseren Auswahlprozess.
- Arbeiten bei ProductDock
- Newsroom
- News
Folgen Sie unseren neuesten Updates und Veröffentlichungen, damit Sie stets über die aktuellsten Entwicklungen von ProductDock informiert sind.
- Events
Vertiefen Sie Ihr Wissen, indem Sie sich mit Gleichgesinnten vernetzen und an unseren nächsten Veranstaltungen Erfahrungen mit Experten austauschen.
- News
- Blog
- Kontakt

02. Juli 2026 •3 minutes read
Apache Solr deep dive: From full-text search to distributed search architecture
Nemanja Marić
Software Engineer
In the first part of our Search Trilogy, we explored Azure AI Search and how Microsoft combines traditional search, AI enrichment, and vector-based retrieval into a managed cloud solution.
In this second part, we shift the focus to Apache Solr — one of the most widely adopted enterprise search platforms built on Apache Lucene. While Azure AI Search provides a managed cloud-native experience, Solr offers deep flexibility, advanced search capabilities, and full control over distributed search infrastructure.
Apache Solr powers search experiences for organizations such as Netflix, Disney, Bloomberg, eBay, SAP Hybris, and Instagram, proving itself a mature, highly scalable search engine for enterprise environments.
Why Apache Solr?
Traditional SQL databases are not optimized for modern search workloads.

Although SQL queries can support simple filtering and text matching, enterprise applications often require:
- Full-text search
- Multi-language support
- Synonyms and stemming
- Relevance ranking
- Typo tolerance
- Distributed search
- Extremely fast retrieval across large datasets
This is where Apache Solr becomes valuable.
Unlike relational databases, Solr is designed specifically for document retrieval and large-scale search operations.
Key advantages include:
- Advanced full-text search
- Relevance scoring with BM25 and TF-IDF
- Faceted search
- High availability
- Horizontal scalability with SolrCloud
- Efficient inverted indexes
- Fast search performance even with billions of documents
Solr is especially suitable for:
- E-commerce platforms
- News and media portals
- Documentation systems
- Knowledge bases
- Product catalogs
- Large enterprise search systems
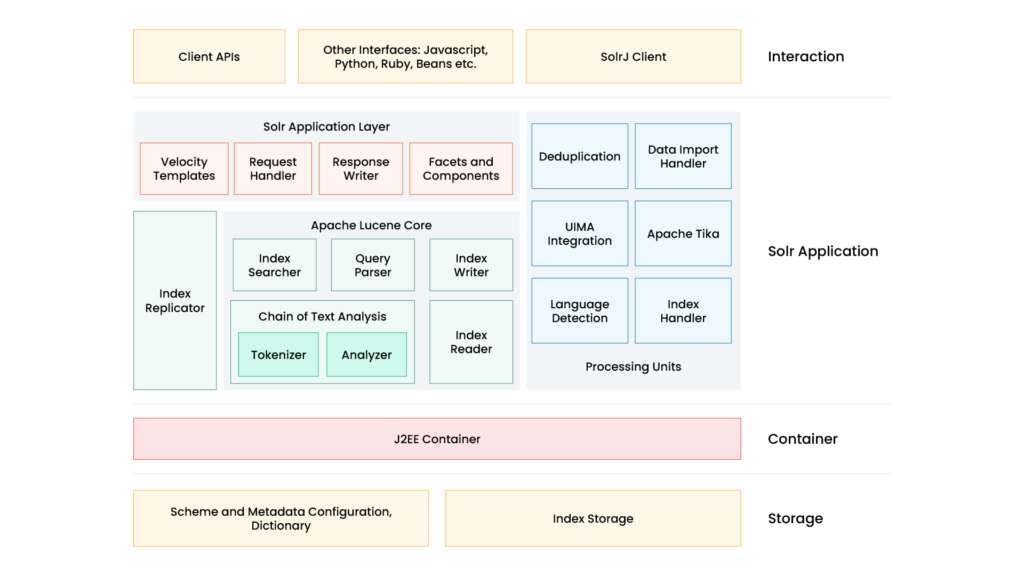
Apache Solr architecture
Apache Solr is built on top of Apache Lucene.
Lucene provides the low-level indexing and retrieval engine, while Solr adds enterprise-grade features such as:
- HTTP APIs
- Distributed search
- Clustering
- Schema management
- Analytics
- Monitoring
- High availability
- Faceting and filtering
- AI-related search features
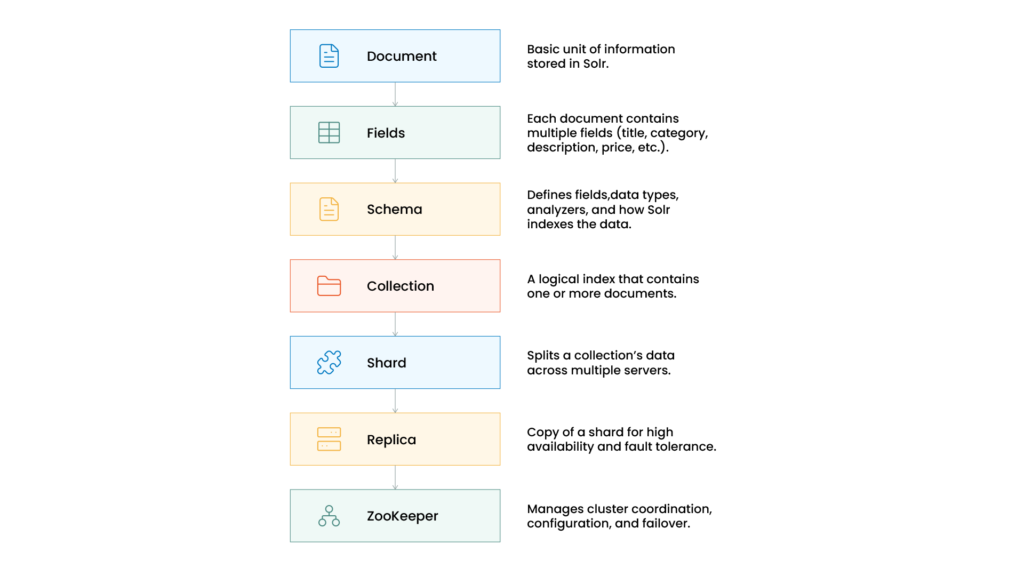
At a high level, the architecture consists of:
- Solr nodes
- Collections
- Shards
- Replicas
- ZooKeeper
- Lucene indexes
Core components
How Apache Solr works
Indexing flow
The indexing process begins when a client sends documents to Solr using the /update endpoint.
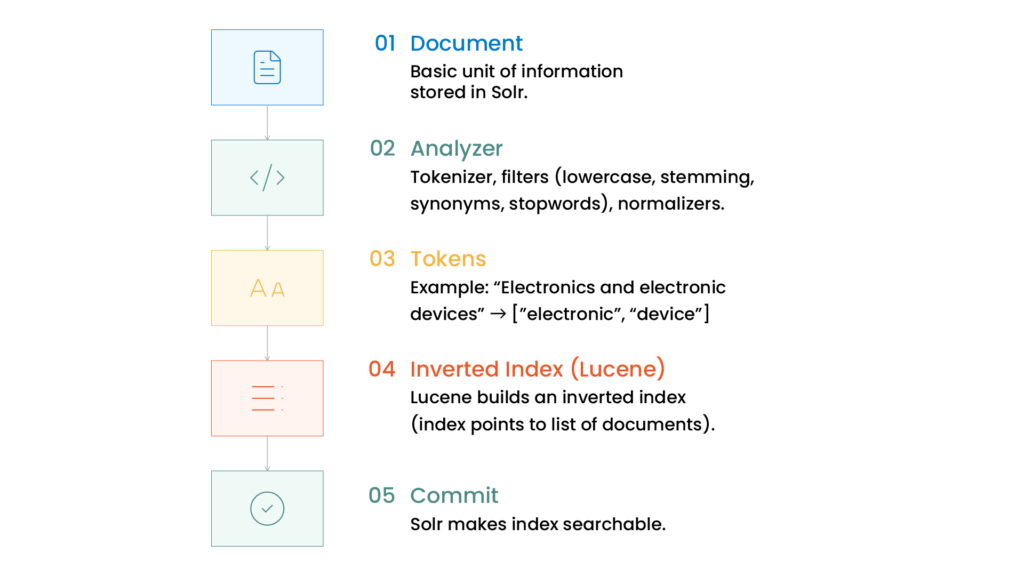
Example flow:
- Client sends document
- Solr transforms it into a SolrInputDocument
- Text analyzers process the content
- Lucene creates inverted indexes
- Solr commits changes and makes data searchable
During analysis, Solr applies:
- Tokenization
- Lowercasing
- Stopword removal
- Synonym handling
- Stemming
Example:
"Electronics and electronic devices"
→ ["electronic", "device"]
This processing significantly improves search relevancy.
Searching flow
Search requests are typically sent through HTTP APIs.
Example query:
/solr/products/select?q=electronics&fq=category:phones&sort=price ascThe process:
- Request Handler processes the query
- Solr receives a request
- Query Parser converts input into Lucene query objects
- Filters are applied separately for caching efficiency
- Lucene performs a search against indexes
- Results are ranked and returned
Solr supports multiple query parsers:

The fq parameter is especially important because filter queries are cached independently, improving performance for repeated searches.
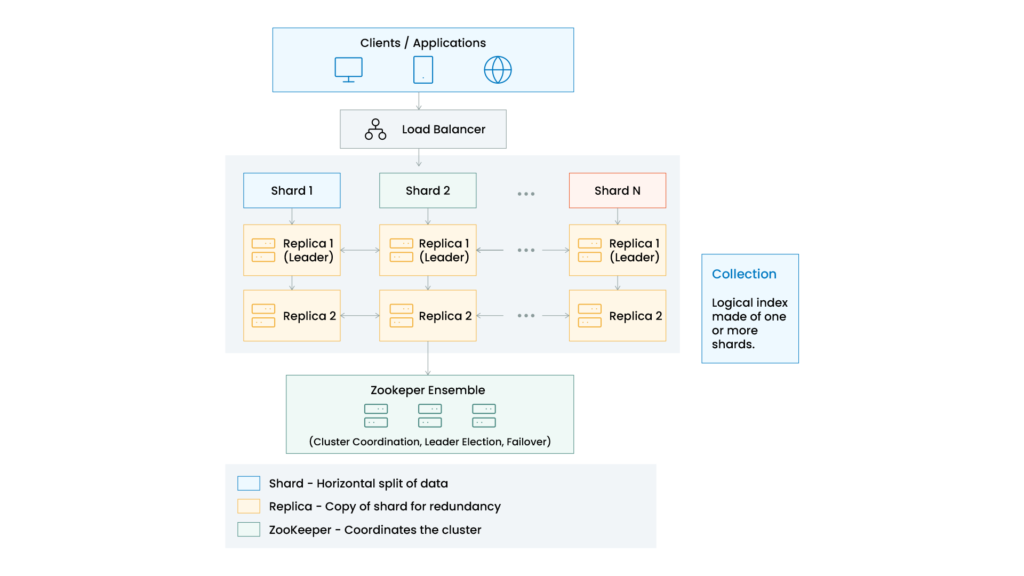
Solr vs SolrCloud
Standalone Solr works well for development and smaller systems.
However, enterprise production environments usually require:
- High availability
- Fault tolerance
- Distributed indexing
- Distributed querying
- Horizontal scaling
This is where SolrCloud comes in.
SolrCloud transforms multiple Solr nodes into a distributed search cluster.
Key concepts:
- Data split into shards
- Each shard has replicas
- ZooKeeper manages cluster coordination
- Automatic failover support
- Distributed querying across nodes
This architecture enables massive scalability and resilience.
AI features in Apache Solr
Modern search platforms increasingly integrate AI and semantic search capabilities.
Apache Solr supports AI-oriented search scenarios through:

Although Solr does not provide built-in AI enrichment like Azure AI Search, it offers strong flexibility for custom AI pipelines.
Practical example: Running SolrCloud with Docker Compose
One of the easiest ways to start experimenting with distributed search is through Docker.
The following example creates:
- One ZooKeeper node
- Two Solr nodes
- Shared Docker network
- Persistent storage volumes
version: "3.8"
networks:
solr-net:
driver: bridge
volumes:
zk-data:
solr1-data:
solr2-data:
services:
zk:
image: zookeeper:3.8
container_name: zk
hostname: zk
environment:
ZOO_MY_ID: 1
ZOO_CLIENT_PORT: 2181
ZOO_TICK_TIME: 2000
ZOO_4LW_COMMANDS_WHITELIST: mntr,conf,ruok
volumes:
- zk-data:/data
networks:
- solr-net
ports:
- "2181:2181"
solr1:
image: solr:9.0
container_name: solr1
hostname: solr1
command: solr -f -c -z zk:2181
ports:
- "8983:8983"
volumes:
- solr1-data:/var/solr
environment:
- SOLR_HEAP=1g
- SOLR_HOST=solr1
networks:
- solr-net
solr2:
image: solr:9.0
container_name: solr2
hostname: solr2
command: solr -f -c -z zk:2181
ports:
- "7574:8983"
volumes:
- solr2-data:/var/solr
environment:
- SOLR_HEAP=1g
- SOLR_HOST=solr2
networks:
- solr-net
To start the cluster:
docker compose up -dOnce started:
- Solr node 1 → http://localhost:8983
- Solr node 2 → http://localhost:7574
This setup provides a practical introduction to:
- SolrCloud
- Distributed indexing
- Replication
- ZooKeeper coordination
- Multi-node search clusters
Final thoughts
Apache Solr remains one of the most powerful and mature enterprise search platforms available today.
Compared to traditional SQL search, Solr delivers:
- Better relevancy
- Faster retrieval
- Distributed scalability
- Advanced text analysis
- AI-ready search capabilities
Compared to Azure AI Search, Solr offers:
- Greater infrastructure control
- Open-source flexibility
- Custom deployment options
- Deep query customization
At the same time, it also requires more operational ownership, especially around cluster management, scaling, and maintenance.
For organizations building:
- Large-scale search systems
- E-commerce platforms
- Knowledge retrieval systems
- AI-enhanced search applications
Apache Solr remains a highly relevant and battle-tested solution.
In the next part of the Search Trilogy, we will explore Elasticsearch and compare its architecture, indexing model, distributed capabilities, and AI ecosystem with both Azure AI Search and Apache Solr.
Tags:Skip tags

Nemanja Marić
Software EngineerNemanja Marić is a software engineer with 6 years of hands-on experience in building robust and scalable applications. He holds a BSc in Software Engineering and specializes primarily in Java and Spring. Along the way, he had also explored C#, React, Cloud Computing, and Flutter. He approaches software development with genuine joy and a passion for creating impactful solutions by building scalable, robust, and high-quality software.
Related posts.

Backend, Industry trends, KI
MCP + RAG: Semantic code search over your GitHub repos
Nemanja Vasić• 16. Juli 2026
Find out more
KI
AI in retail (part 1): Better experiences, but bigger risks
Marta Costa• 17. Juni 2026
Find out more