 ENG
ENG- Branchen
- Finanzen
Nearshore-Softwareentwicklung für den Finanzsektor – sicher, skalierbar und Compliance-gerechte Lösungen für Banking, Zahlungsverkehr und APIs.
- Einzelhandel
Softwareentwicklung für den Einzelhandel – E-Commerce, Kassensysteme, Logistik und KI-gestützte Personalisierung durch unsere Nearshore-Engineering-Teams.
- Verarbeitende Industrie
Nearshore-Softwareentwicklung für die Industrie – ERP-Systeme, IoT-Plattformen und Automatisierungstools zur Optimierung industrieller Abläufe.
- Finanzen
- Was wir tun
- Services
- Technologien
- Kooperationsmodelle
Kooperationsmodelle passend zu Ihren Bedürfnissen: Komplette Nearshoring Teams, deutschsprachige Experten vor Ort mit Nearshoring-Teams oder gemischte Teams mit unseren Partnern.
- Arbeitsweise
Durch enge Zusammenarbeit mit Ihrem Unternehmen schaffen wir maßgeschneiderte Lösungen, die auf Ihre Anforderungen abgestimmt sind und zu nachhaltigen Ergebnissen führen.
- Über uns
- Wer wir sind
Wir sind ein Full-Service Nearshoring-Anbieter für digitale Softwareprodukte, ein perfekter Partner mit deutschsprachigen Experten vor Ort, Ihre Business-Anforderungen stets im Blick
- Unser Team
Das ProductDock Team ist mit modernen Technologien und Tools vertraut und setzt seit 15 Jahren zusammen mit namhaften Firmen erfolgreiche Projekte um.
- Wozu Nearshoring
Wir kombinieren Nearshore- und Fachwissen vor Ort, um Sie während Ihrer gesamten digitalen Produktreise optimal zu unterstützen. Lassen Sie uns Ihr Business gemeinsam auf das nächste digitale Level anheben.
- Wer wir sind
- Unser Leistungen
- Karriere
- Arbeiten bei ProductDock
Unser Fokus liegt auf der Förderung von Teamarbeit, Kreativität und Empowerment innerhalb unseres Teams von über 120 talentierten Tech-Experten.
- Offene Stellen
Begeistert es dich, an spannenden Projekten mitzuwirken und zu sehen, wie dein Einsatz zu erfolgreichen Ergebnissen führt? Dann bist du bei uns richtig.
- Info Guide für Kandidaten
Wie suchen wir unsere Crew-Mitglieder aus? Wir sehen dich als Teil unserer Crew und erklären gerne unseren Auswahlprozess.
- Arbeiten bei ProductDock
- Newsroom
- News
Folgen Sie unseren neuesten Updates und Veröffentlichungen, damit Sie stets über die aktuellsten Entwicklungen von ProductDock informiert sind.
- Events
Vertiefen Sie Ihr Wissen, indem Sie sich mit Gleichgesinnten vernetzen und an unseren nächsten Veranstaltungen Erfahrungen mit Experten austauschen.
- News
- Blog
- Kontakt

17. Juli 2025 •4 minutes read
How to use MuleSoft for efficient CSV data streaming
Saša Jovanović
Software Engineer
A common challenge in integrations involves automating the transfer and transformation of large datasets between remote systems. One of our clients recently encountered this issue, requiring them to move CSV data from one SFTP server to another while maintaining data integrity and performance. In this post, I’ll walk you through our solution using a simplified showcase. It does not use production-grade configurations or include client-specific logic.
Before we dive into the solution, let’s describe the challenge and key constraints.
The challenge
To successfully handle this integration problem we need to address the following four major requirements:
- Retrieve a large CSV file from a source SFTP server;
- Transform the data to match a target format (e.g., column mapping, data type conversion);
- Preserve the original record order throughout processing;
- Write the transformed data to a new file on a destination SFTP server;
keeping in mind that:
- The CSV files can be very large, often containing hundreds of thousands of records;
- The entire file must not be loaded into memory at once—the solution had to be stream-based and memory-efficient;
- Parallel processing is not allowed, as maintaining record order was critical for downstream systems.
The solution
Local setup
To simulate the integration environment, I will use Docker containers to simulate the source and target SFTP servers. This will allow us to develop and test locally with ease.
sftp-origin: Source SFTP server container
docker run -p 2222:22 -d --name sftp-origin -v C:/Users/PC/sftpdata/origin:/home/foo/upload atmoz/sftp foo:password:::upload
sftp-remote: Destination SFTP server container
docker run -p 2223:22 -d --name sftp-remote -v C:/Users/PC/sftpdata/remote:/home/foo/upload atmoz/sftp foo:password:::uploadEach container maps a local folder to its remote /upload directory for straightforward file management.
For inspecting files and performing file transfers, you can use an SFTP client (e.g. I’m using FileZilla) with the following parameters:
- Host: localhost
- Port: 2222 or 2223 (depending on the target SFTP container)
- Username: foo
- Password: password
- Remote directory: /upload
Sample data
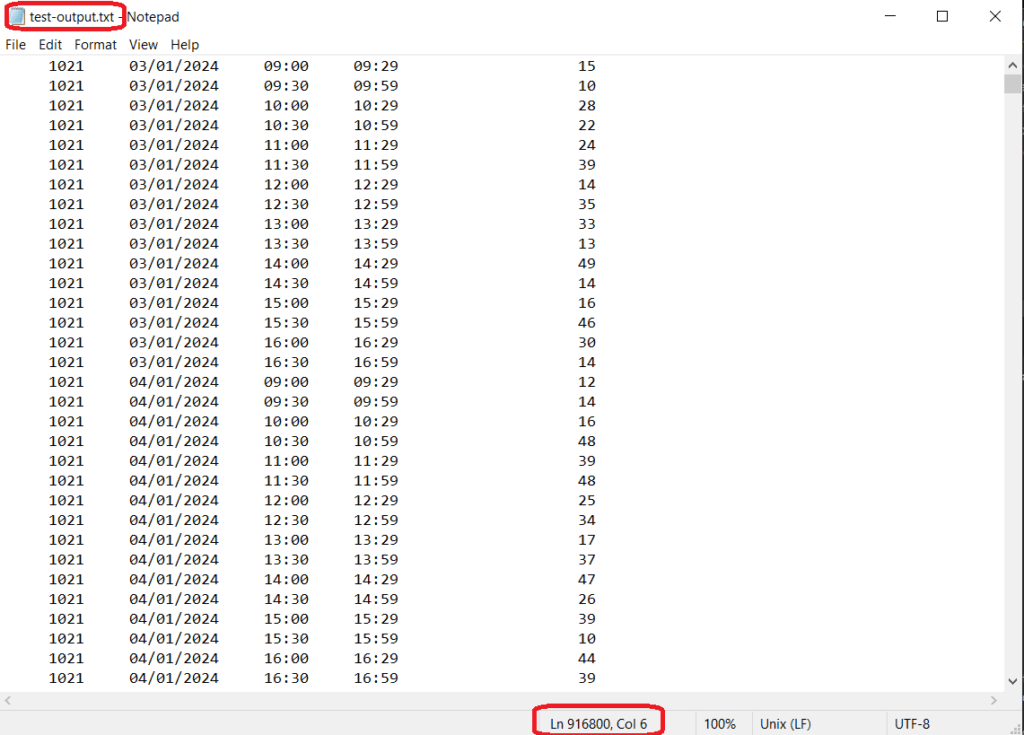
To test our implementation, we’ll use a test.csv file that contains 916,800 records. Each record represents a 30-minute time window for a specific store on a particular date, along with the visitor count.
store,date,start,end,visitors<br>1021,03/01/2024,09:00,09:29,15<br>1021,03/01/2024,09:30,09:59,10<br>1021,03/01/2024,10:00,10:29,28<br>1021,03/01/2024,10:30,10:59,22<br>1021,03/01/2024,11:00,11:29,24<br>1021,03/01/2024,11:30,11:59,39<br>1021,03/01/2024,12:00,12:29,14<br>1021,03/01/2024,12:30,12:59,35<br>...<br>The structure of this dataset prioritizes the strict order because it is crucial for tracking visitor activity for each store over time.
MuleSoft implementation
Now, let’s take a closer look at the MuleSoft flow that powers this integration; from streaming and transforming data to writing the results to the destination SFTP server.
> Note: For clarity, I’ll omit error handling, but in production you should always include robust error handling, retries, and logging.
Here is our flow:
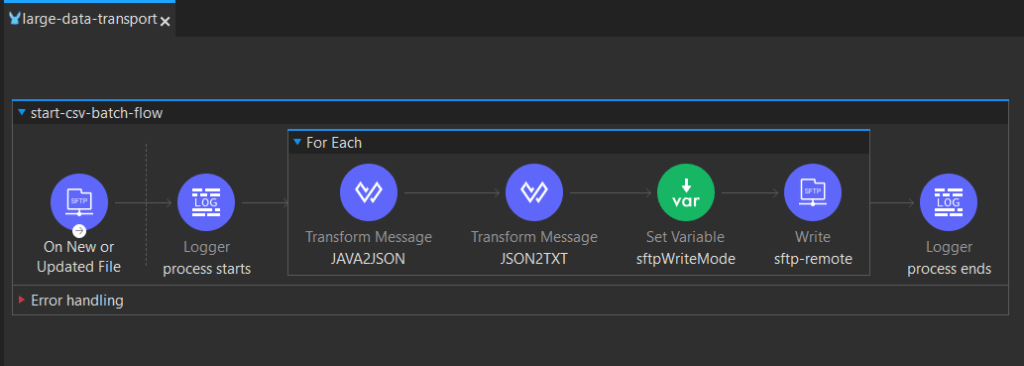
1. SFTP Listener
<sftp:listener doc:name="On New or Updated File" doc:id="1eeadde4-f731-476d-a7b3-c63852fbdd47" config-ref="sftpOriginConfig" outputMimeType='application/csv; bodystartlinenumber=1; headerlinenumber=0; streaming=true; separator=","; header=true' moveToDirectory="/upload/archive" renameTo='#["test_" ++ now() as String {format: "yyyy-MM-dd_HH-mm-ss"}]'><br> <non-repeatable-stream /><br> <scheduling-strategy ><br> <fixed-frequency frequency="5" timeUnit="MINUTES" /><br> </scheduling-strategy><br> <sftp:matcher filenamePattern="*.csv"/><br></sftp:listener><br>For detecting new files, we will use scheduled polling, every 5 minutes and configure it to look for CSV files only. To prevent loading the complete file into memory — crucial for large files, the streaming=true parameter ensures line-by-line stream processing and avoids memory overload. Also, by using the <non-repeatable-stream /> strategy we will read/consume our payload (each chunk) only once, aiming for better performance, without needing to keep it in the memory for further processing.
For post-read actions we want to:
- Rename the file using custom format to include the timestamp: test_yyyy-MM-dd_HH-mm-ss.csv
- Archive it to /upload/archive directory
2. Chunked processing
After we have enabled streaming and chosen a streaming strategy, we want to process it in chunks. For this, we use foreach loop and configure the batchSize. We want to partition the input array into sub-collections of a specified size.
<foreach doc:name="For Each" doc:id="cad2e08c-f764-4968-9824-53abdfb24ae3" batchSize="2000">
...
</foreach><br>The `batchSize` provided is for example purposes only. The ideal value will vary based on the dataset’s structure, the application’s memory usage, and observed performance metrics.
So, if the input has 100,000 records:
- Mule splits it into 50 chunks of 2000 records each (with the last chunk possibly smaller)
- Each chunk becomes a payload in the
scope - You can apply transformations to each chunk independently
With this, we achieve:
- High throughput
- Low memory footprint
- Decreased I/O overhead
3. Determining write mode
Since we want to have the output in one file, we dynamically set whether to overwrite or append to the destination file using:
<foreach doc:name="For Each" doc:id="cad2e08c-f764-4968-9824-53abdfb24ae3" batchSize="2000">
...
<set-variable value='#[if(vars.counter == 1) "OVERWRITE" else "APPEND"]' variableName="sftpWriteMode" />
...
</foreach><br>- First chunk: OVERWRITE -> creates a new file
- Subsequent chunks: APPEND -> extends the same existing file
This strategy avoids fragmentation and ensures data is written cumulatively in the correct order.
4. Writing to remote SFTP
Each batch of 2000 records is written in a single SFTP operation, which minimizes disk I/O and accelerates the overall process.
Output
The final exported file on the destination SFTP server mirrors the source structure but reflects the applied transformations (adding space between the columns). Data is written in the original order, in a memory-efficient manner, with minimal I/O overhead.
Conclusion
By leveraging streaming, chunked processing, and smart write-mode handling, we created a scalable MuleSoft integration that:
- Handles large CSV files efficiently
- Preserves record order throughout processing
- Reduces memory usage and I/O bottlenecks
- Is clean, maintainable, and production-ready
This solution is a strong example of how to design performant integrations in resource-constrained environments.
To see the complete source code and this deployment process in action, visit the GitHub repository. Feel free to explore, fork, or contribute to the project!
Tags:Skip tags

Saša Jovanović
Software EngineerSaša Jovanović is a software developer and content creator who has been part of the ProductDock team since 2022. His primary expertise lies in MuleSoft development, where he focuses on building reliable and scalable API integrations. With a strong background in backend systems, he is passionate about clean code and efficient workflows, consistently exploring new technologies to enhance development practices.
Related posts.

Allgemein, Backend
The C4 model for visualizing software architecture
Ladislav Milunović• 02. Apr. 2026
Find out more
Backend
A practical overview of SOLID design principles in Java
Nemanja Marić• 25. März 2026
Find out more