 DE
DE- Industries
- Finance
Nearshore software development for finance—secure, scalable, and compliant solutions for banking, payments, and APIs.
- Retail
Retail software development services—e-commerce, POS, logistics, and AI-driven personalization from nearshore engineering teams.
- Manufacturing
Nearshore manufacturing software development—ERP systems, IoT platforms, and automation tools to optimize industrial operations.
- Finance
- What we do
- Services
- Software modernization services
- Cloud solutions
- AI – Artificial intelligence
- Idea validation & Product development services
- Digital solutions
- Integration for digital ecosystems
- A11y – Accessibility
- QA – Test development
- Technologies
- Front-end
- Back-end
- DevOps & CI/CD
- Cloud
- Mobile
- Collaboration models
- Collaboration models
Explore collaboration models customized to your specific needs: Complete nearshoring teams, Local heroes from partners with the nearshoring team, or Mixed tech teams with partners.
- Way of work
Through close collaboration with your business, we create customized solutions aligned with your specific requirements, resulting in sustainable outcomes.
- Collaboration models
- Services
- About Us
- Who we are
We are a full-service nearshoring provider for digital software products, uniquely positioned as a high-quality partner with native-speaking local experts, perfectly aligned with your business needs.
- Meet our team
ProductDock’s experienced team proficient in modern technologies and tools, boasts 15 years of successful projects, collaborating with prominent companies.
- Why nearshoring
Elevate your business efficiently with our premium full-service software development services that blend nearshore and local expertise to support you throughout your digital product journey.
- Who we are
- Our work
- Career
- Life at ProductDock
We’re all about fostering teamwork, creativity, and empowerment within our team of over 120 incredibly talented experts in modern technologies.
- Open positions
Do you enjoy working on exciting projects and feel rewarded when those efforts are successful? If so, we’d like you to join our team.
- Hiring guide
How we choose our crew members? We think of you as a member of our crew. We are happy to share our process with you!
- Rookie boot camp internship
Start your IT journey with Rookie boot camp, our paid internship program where students and graduates build skills, gain confidence, and get real-world experience.
- Life at ProductDock
- Newsroom
- News
Stay engaged with our most recent updates and releases, ensuring you are always up-to-date with the latest developments in the dynamic world of ProductDock.
- Events
Expand your expertise through networking with like-minded individuals and engaging in knowledge-sharing sessions at our upcoming events.
- News
- Blog
- Get in touch

17. Jul 2025 •4 minutes read
How to use MuleSoft for efficient CSV data streaming
Saša Jovanović
Software Engineer
A common challenge in integrations involves automating the transfer and transformation of large datasets between remote systems. One of our clients recently encountered this issue, requiring them to move CSV data from one SFTP server to another while maintaining data integrity and performance. In this post, I’ll walk you through our solution using a simplified showcase. It does not use production-grade configurations or include client-specific logic.
Before we dive into the solution, let’s describe the challenge and key constraints.
The challenge
To successfully handle this integration problem we need to address the following four major requirements:
- Retrieve a large CSV file from a source SFTP server;
- Transform the data to match a target format (e.g., column mapping, data type conversion);
- Preserve the original record order throughout processing;
- Write the transformed data to a new file on a destination SFTP server;
keeping in mind that:
- The CSV files can be very large, often containing hundreds of thousands of records;
- The entire file must not be loaded into memory at once—the solution had to be stream-based and memory-efficient;
- Parallel processing is not allowed, as maintaining record order was critical for downstream systems.
The solution
Local setup
To simulate the integration environment, I will use Docker containers to simulate the source and target SFTP servers. This will allow us to develop and test locally with ease.
sftp-origin: Source SFTP server container
docker run -p 2222:22 -d --name sftp-origin -v C:/Users/PC/sftpdata/origin:/home/foo/upload atmoz/sftp foo:password:::upload
sftp-remote: Destination SFTP server container
docker run -p 2223:22 -d --name sftp-remote -v C:/Users/PC/sftpdata/remote:/home/foo/upload atmoz/sftp foo:password:::uploadEach container maps a local folder to its remote /upload directory for straightforward file management.
For inspecting files and performing file transfers, you can use an SFTP client (e.g. I’m using FileZilla) with the following parameters:
- Host: localhost
- Port: 2222 or 2223 (depending on the target SFTP container)
- Username: foo
- Password: password
- Remote directory: /upload
Sample data
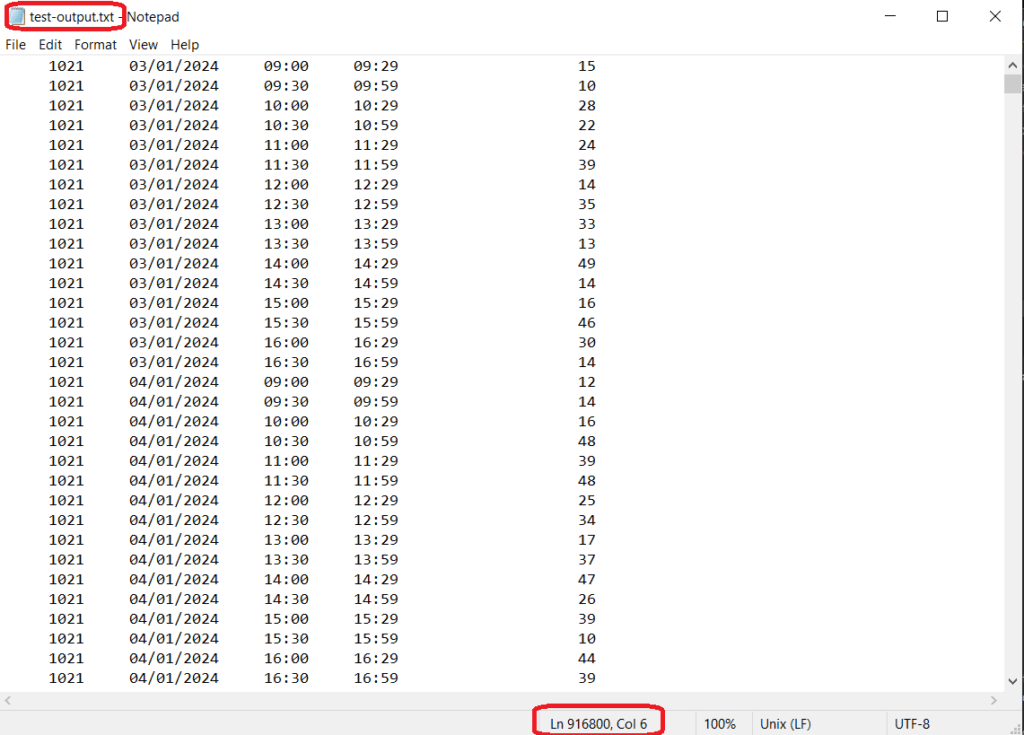
To test our implementation, we’ll use a test.csv file that contains 916,800 records. Each record represents a 30-minute time window for a specific store on a particular date, along with the visitor count.
store,date,start,end,visitors
1021,03/01/2024,09:00,09:29,15
1021,03/01/2024,09:30,09:59,10
1021,03/01/2024,10:00,10:29,28
1021,03/01/2024,10:30,10:59,22
1021,03/01/2024,11:00,11:29,24
1021,03/01/2024,11:30,11:59,39
1021,03/01/2024,12:00,12:29,14
1021,03/01/2024,12:30,12:59,35
...
The structure of this dataset prioritizes the strict order because it is crucial for tracking visitor activity for each store over time.
MuleSoft implementation
Now, let’s take a closer look at the MuleSoft flow that powers this integration; from streaming and transforming data to writing the results to the destination SFTP server.
> Note: For clarity, I’ll omit error handling, but in production you should always include robust error handling, retries, and logging.
Here is our flow:
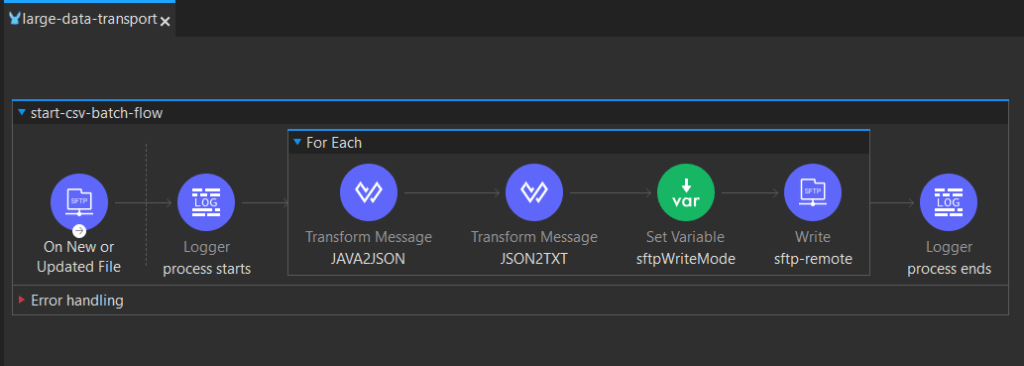
1. SFTP Listener
<sftp:listener doc:name="On New or Updated File" doc:id="1eeadde4-f731-476d-a7b3-c63852fbdd47" config-ref="sftpOriginConfig" outputMimeType='application/csv; bodystartlinenumber=1; headerlinenumber=0; streaming=true; separator=","; header=true' moveToDirectory="/upload/archive" renameTo='#["test_" ++ now() as String {format: "yyyy-MM-dd_HH-mm-ss"}]'>
<non-repeatable-stream />
<scheduling-strategy >
<fixed-frequency frequency="5" timeUnit="MINUTES" />
</scheduling-strategy>
<sftp:matcher filenamePattern="*.csv"/>
</sftp:listener>
For detecting new files, we will use scheduled polling, every 5 minutes and configure it to look for CSV files only. To prevent loading the complete file into memory — crucial for large files, the streaming=true parameter ensures line-by-line stream processing and avoids memory overload. Also, by using the <non-repeatable-stream /> strategy we will read/consume our payload (each chunk) only once, aiming for better performance, without needing to keep it in the memory for further processing.
For post-read actions we want to:
- Rename the file using custom format to include the timestamp: test_yyyy-MM-dd_HH-mm-ss.csv
- Archive it to /upload/archive directory
2. Chunked processing
After we have enabled streaming and chosen a streaming strategy, we want to process it in chunks. For this, we use foreach loop and configure the batchSize. We want to partition the input array into sub-collections of a specified size.
<foreach doc:name="For Each" doc:id="cad2e08c-f764-4968-9824-53abdfb24ae3" batchSize="2000">
...
</foreach>
The `batchSize` provided is for example purposes only. The ideal value will vary based on the dataset’s structure, the application’s memory usage, and observed performance metrics.
So, if the input has 100,000 records:
- Mule splits it into 50 chunks of 2000 records each (with the last chunk possibly smaller)
- Each chunk becomes a payload in the <foreach> scope
- You can apply transformations to each chunk independently
With this, we achieve:
- High throughput
- Low memory footprint
- Decreased I/O overhead
3. Determining write mode
Since we want to have the output in one file, we dynamically set whether to overwrite or append to the destination file using:
<foreach doc:name="For Each" doc:id="cad2e08c-f764-4968-9824-53abdfb24ae3" batchSize="2000">
...
<set-variable value='#[if(vars.counter == 1) "OVERWRITE" else "APPEND"]' variableName="sftpWriteMode" />
...
</foreach>
- First chunk: OVERWRITE -> creates a new file
- Subsequent chunks: APPEND -> extends the same existing file
This strategy avoids fragmentation and ensures data is written cumulatively in the correct order.
4. Writing to remote SFTP
Each batch of 2000 records is written in a single SFTP operation, which minimizes disk I/O and accelerates the overall process.
Output
The final exported file on the destination SFTP server mirrors the source structure but reflects the applied transformations (adding space between the columns). Data is written in the original order, in a memory-efficient manner, with minimal I/O overhead.
Conclusion
By leveraging streaming, chunked processing, and smart write-mode handling, we created a scalable MuleSoft integration that:
- Handles large CSV files efficiently
- Preserves record order throughout processing
- Reduces memory usage and I/O bottlenecks
- Is clean, maintainable, and production-ready
This solution is a strong example of how to design performant integrations in resource-constrained environments.
To see the complete source code and this deployment process in action, visit the GitHub repository. Feel free to explore, fork, or contribute to the project!
Tags:Skip tags

Saša Jovanović
Software EngineerSaša Jovanović is a software developer and content creator who has been part of the ProductDock team since 2022. His primary expertise lies in MuleSoft development, where he focuses on building reliable and scalable API integrations. With a strong background in backend systems, he is passionate about clean code and efficient workflows, consistently exploring new technologies to enhance development practices.
Related posts.

Backend, General
The C4 model for visualizing software architecture
Ladislav Milunović• 02. Apr 2026
Find out more
Backend
A practical overview of SOLID design principles in Java
Nemanja Marić• 25. Mar 2026
Find out more