- Industries
- Finance
Nearshore software development for finance—secure, scalable, and compliant solutions for banking, payments, and APIs.
- Retail
Retail software development services—e-commerce, POS, logistics, and AI-driven personalization from nearshore engineering teams.
- Manufacturing
Nearshore manufacturing software development—ERP systems, IoT platforms, and automation tools to optimize industrial operations.
- Finance
- What we do
- Services
- Software modernization services
- Cloud solutions
- AI – Artificial intelligence
- Idea validation & Product development services
- Digital solutions
- Integration for digital ecosystems
- A11y – Accessibility
- QA – Test development
- Technologies
- Front-end
- Back-end
- DevOps & CI/CD
- Cloud
- Mobile
- Collaboration models
- Collaboration models
Explore collaboration models customized to your specific needs: Complete nearshoring teams, Local heroes from partners with the nearshoring team, or Mixed tech teams with partners.
- Way of work
Through close collaboration with your business, we create customized solutions aligned with your specific requirements, resulting in sustainable outcomes.
- Collaboration models
- Services
- About Us
- Who we are
We are a full-service nearshoring provider for digital software products, uniquely positioned as a high-quality partner with native-speaking local experts, perfectly aligned with your business needs.
- Meet our team
ProductDock’s experienced team proficient in modern technologies and tools, boasts 15 years of successful projects, collaborating with prominent companies.
- Why nearshoring
Elevate your business efficiently with our premium full-service software development services that blend nearshore and local expertise to support you throughout your digital product journey.
- Who we are
- Our work
- Career
- Life at ProductDock
We’re all about fostering teamwork, creativity, and empowerment within our team of over 120 incredibly talented experts in modern technologies.
- Open positions
Do you enjoy working on exciting projects and feel rewarded when those efforts are successful? If so, we’d like you to join our team.
- Hiring guide
How we choose our crew members? We think of you as a member of our crew. We are happy to share our process with you!
- Rookie boot camp internship
Start your IT journey with Rookie boot camp, our paid internship program where students and graduates build skills, gain confidence, and get real-world experience.
- Life at ProductDock
- Newsroom
- News
Stay engaged with our most recent updates and releases, ensuring you are always up-to-date with the latest developments in the dynamic world of ProductDock.
- Events
Expand your expertise through networking with like-minded individuals and engaging in knowledge-sharing sessions at our upcoming events.
- News
- Blog
- Get in touch
AWS cost optimization: How we saved $750+/month and cut our bill by 40%.
When we first architected our real-time production dashboard, we chose Amazon Timestream Live Analytics as our time-series database solution. The serverless architecture and pay-per-query pricing model seemed ideal, offering flexibility without requiring us to manage instances or pay when not using it, while allowing us to extract our data into 5-minute interval chunks to visualize production trends over time. However, as our application scaled and query volume increased, the cost of millions of frequent, small queries became a significant financial burden, forcing us to re-evaluate.
This brought us to a critical decision. We evaluated two options: migrating to Amazon Timestream for InfluxDB, a newer engine with instance and storage based pricing and significantly improved read performance which projected monthly savings of $300-$400 (mainly by eliminating the per-query cost); or building a completely custom solution using foundational services like DynamoDB and Lambda to save even more and solve other core architectural problems such as data duplication and maintaining our state in sync.
We chose the custom path. What we discovered was that our initial choice, Timestream, which once seemed like a perfect fit, had in practice become a liability: expensive, slow, and unnecessarily complex. So, we tore it out and rebuilt the feature, pushing our total savings to over $750/month and cutting our entire AWS account bill by a staggering 40%.
Here’s the story.
The Timestream trap: costly AWS architecture mistakes.
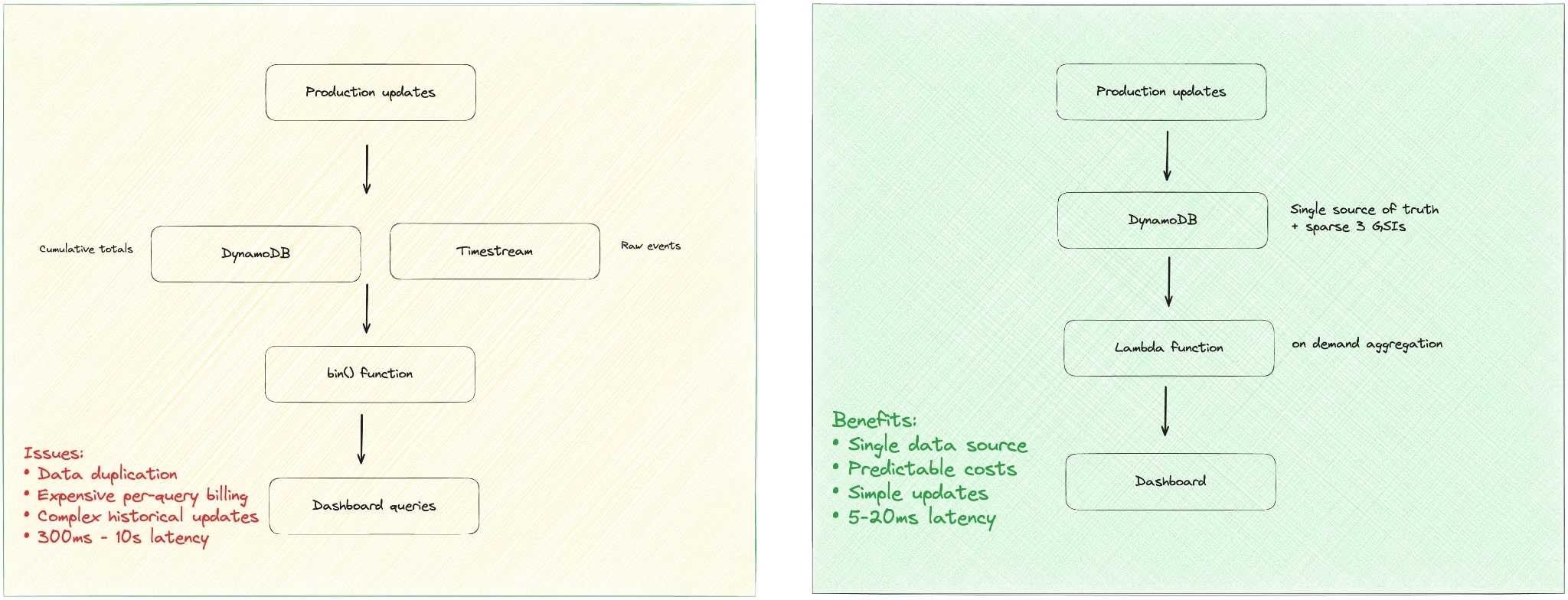
Our initial implementation is based on an entity called WorkcenterPeriod, which is stored in DynamoDB and maintains a cumulative production total for periods of active production and updated every minute. The architecture consisted of two parallel processes:
1. DynamoDB updates: Period totals were calculated as previous total + new update = new total
2.Timestream ingestion: Each individual production update was also pushed into Timestream as a raw event.
We then relied on Timestream’s built-in bin() function at query time to group these raw events into 5-minute intervals for our charts. This setup seemed logical, but it quickly turned into a technical and financial headache.
- Expensive reads: Our original Timestream engine billed per query scan, often in blocks. A simple dashboard polling once per minute racked up costs surprisingly fast.
- Slow queries: Our real-world query latencies averaged between 300 ms and 1 second. When we needed to query millions of rows for historical charts, that ballooned to a painful 10 seconds.
- Data duplication: We were maintaining the same state in two places: DynamoDB held the cumulative total, while Timestream stored the raw events solely for binned queries.
- Painful historical changes: This was the biggest architectural flaw. If a historical WorkcenterPeriod had to be corrected, we’d have to perform a cascading update in DynamoDB, recalculating every cumulative total from that point forward. Simultaneously, we’d have to find, delete, and “redistribute” the raw events in Timestream to match the new total. This two-part process was incredibly complex, error-prone, and risked putting our two data stores permanently out of sync.
The Pivot: A simpler, smarter solution with DynamoDB + Lambda.
We made the call to ditch Timestream entirely and handle everything in DynamoDB with a smarter design to cut AWS costs and improve efficiency.
The core of the new solution was introducing three sparse Global Secondary Indexes (GSIs) on our DynamoDB table. A sparse index is a clever trick: you create a GSI on an attribute that doesn’t exist on every item in your table. DynamoDB’s magic is that it only includes an item in the GSI if it has that specific attribute. While adding a GSI normally increases write costs (WCUs) for every item write, the sparse nature of our indexes meant this cost was only incurred on the small subset of records relevant to the index, not every single update flowing into the table. Furthermore, we leveraged projection expressions in our queries to retrieve only the attributes we absolutely needed, minimizing read costs. For these reasons, our DynamoDB costs didn’t explode; they merely increased by a manageable $50 per month—a tiny fraction of our total savings.
Instead of relying on Timestream to bin the data at query time, a simple Lambda function now does it on demand. It queries the raw updates from our DynamoDB table and implements custom logic to aggregate them into 5-minute bins in memory, giving us the same result with far better performance and cost.
Going further: Performance optimization enhancements.
Once the core migration was complete, we didn’t stop there. We saw opportunities to optimize our new Lambda-based architecture even further.
- Parallel database queries: For scenarios where we needed data from multiple sources at once, we refactored our Lambda function to fetch data in parallel using Promise.all. Instead of waiting for one query to finish before starting the next, we fired them all off simultaneously. This simple change reduced Lambda execution times and shaved another $40/month off the bill.
- Lambda runtime optimization: We also implemented a key Lambda optimization: initializing heavyweight clients (such as the AWS SDK) outside the main handler function. This allows the connection to be reused across “warm” invocations, avoiding unnecessary setup time on each run.
These performance tweaks, combined with other minor improvements, cut our costs by an additional $150 per month in total.
Results and performance metrics.
Migrating to Timestream for InfluxDB would have been a solid improvement, but the custom solution proved truly transformative. The final difference in cost, performance, and simplicity was night and day.
| Original Setup (Timestream Serverless) | Option B (Timestream for InfluxDB) | Final Solution (DynamoDB + Lambda) | |
|---|---|---|---|
| Monthly Cost | ~$750+ | Estimated ~$250 – $350 | <$50 (often <$30) |
| Read Latency | 300 ms – 10 s | Improved (<50 ms) | 5–20 ms (typically <10 ms) |
| Data Duplication | Yes | Yes | No |
| Complexity | High | High | Medium |
Lessons learned.
This whole experience taught us a few valuable lessons:
- Don’t overengineer. The simplest solution is often the best. A foundational service like DynamoDB, used cleverly, can outperform a specialized, more expensive one and of course it always depends on the use case
- Watch the pricing models. Understanding pricing structures is crucial. Timestream’s original pay-per-query model became a hidden cost driver for our polling pattern, while DynamoDB’s pay-per-read model proved far more predictable and affordable.
- Optimization pays dividends. After the big architectural win, small performance improvements in our Lambda functions compounded into significant additional savings.
FInal thoughts.
Switching from Timestream to an optimized DynamoDB + Lambda architecture cut ~$750/month from our AWS bill, reducing our total account spending by 40%. More importantly, it dramatically simplified our system and provided faster, more predictable performance.
To be clear, this isn’t a knock against AWS Timestream. It’s an incredibly powerful service with advanced functions for complex time-series analysis. The issue was not with the tool but with our specific use case. We were paying for a suite of powerful features when all we really needed was simple storage and on-demand aggregation.
If you’re struggling with a specialized service that feels like overkill, ask your team: Can we solve this with a simpler, foundational service?
For us, the answer was a very clear—and very profitable—yes.