 DE
DE- Industries
- Finance
Nearshore software development for finance—secure, scalable, and compliant solutions for banking, payments, and APIs.
- Retail
Retail software development services—e-commerce, POS, logistics, and AI-driven personalization from nearshore engineering teams.
- Manufacturing
Nearshore manufacturing software development—ERP systems, IoT platforms, and automation tools to optimize industrial operations.
- Finance
- What we do
- Services
- Technologies
- Collaboration models
Explore collaboration models customized to your specific needs: Complete nearshoring teams, Local heroes from partners with the nearshoring team, or Mixed tech teams with partners.
- Way of work
Through close collaboration with your business, we create customized solutions aligned with your specific requirements, resulting in sustainable outcomes.
- About Us
- Who we are
We are a full-service nearshoring provider for digital software products, uniquely positioned as a high-quality partner with native-speaking local experts, perfectly aligned with your business needs.
- Meet our team
ProductDock’s experienced team proficient in modern technologies and tools, boasts 15 years of successful projects, collaborating with prominent companies.
- Our locations
We are ProductDock, a full-service nearshoring provider for digital software products, headquartered in Berlin, with engineering hubs in Lisbon, Novi Sad, Banja Luka, and Doboj.
- Why nearshoring
Elevate your business efficiently with our premium full-service software development services that blend nearshore and local expertise to support you throughout your digital product journey.
- Who we are
- Our work
- Career
- Life at ProductDock
We’re all about fostering teamwork, creativity, and empowerment within our team of over 120 incredibly talented experts in modern technologies.
- Open positions
Do you enjoy working on exciting projects and feel rewarded when those efforts are successful? If so, we’d like you to join our team.
- Candidate info guide
How we choose our crew members? We think of you as a member of our crew. We are happy to share our process with you!
- Life at ProductDock
- Newsroom
- News
Stay engaged with our most recent updates and releases, ensuring you are always up-to-date with the latest developments in the dynamic world of ProductDock.
- Events
Expand your expertise through networking with like-minded individuals and engaging in knowledge-sharing sessions at our upcoming events.
- News
- Blog
- Get in touch

10. Jul 2023 •5 minutes read
Unveiling Apache Beam: A powerful tool for data processing
Bojan Ćorić
Sofware Developer
Working with large and complex datasets presents a number of challenges for developers and data analysts. The size of these datasets can be overwhelming and real-time data adds another layer of complexity. That is where Apache Beam comes in.
Apache Beam is an open-source, unified programming model for batch and streaming data processing pipelines which simplifies large-scale data processing dynamics. It was founded in 2016 when Google decided to move the Google Cloud Dataflow SDKs and runners, along with a set of IO connectors, to Apache Software Foundation.
Apache Beam Portability and Flexibility
One of the biggest advantages of Apache Beam is its portability, and it is portable on several layers:
Apache Beam provides a data processing model that can be used across multiple programming languages, making it highly flexible and versatile, which means that we can choose between various programming languages to write our pipeline, some of them being Java, Python, Go, Scala, and SQL. The Beam model refers to this as SDK.
The pipelines created with Apache Beam can be easily deployed on different runners without any modification. A runner is a data processing engine that runs a data processing pipeline and is responsible for scheduling, managing, and executing the pipeline on a specific distributed processing platform such as Google Cloud Dataflow, Apache Flink, or Apache Spark. To identify the capabilities of individual runners, check the Beam capability matrix.
With Apache Beam, developers can write data processing logic capable of handling both bounded and unbounded data, making it highly adaptable to various data types and sources. Bounded data, historically known as batch data, refers to finite data with a fixed size. On the other hand, unbounded data refers to streaming data that does not have a predefined beginning or end and can be continuously generated or updated over time.
Apache Beam provides a simple and flexible programming model that abstracts away the underlying implementation details of the processing engine. The model is based on three main concepts: Pipeline, PCollection, and PTransform.
Pipeline
The Pipeline abstraction encapsulates all the data and steps in your data processing task. It is a graph (a directed acyclic graph) of all the data and computations in your data processing task. It includes reading input data from various sources, applying different processing steps in order to prepare desired output form, and eventually writing output data to the desired sink.
The following image shows an example of a pipeline that counts the number of occurrences of words in a text file.
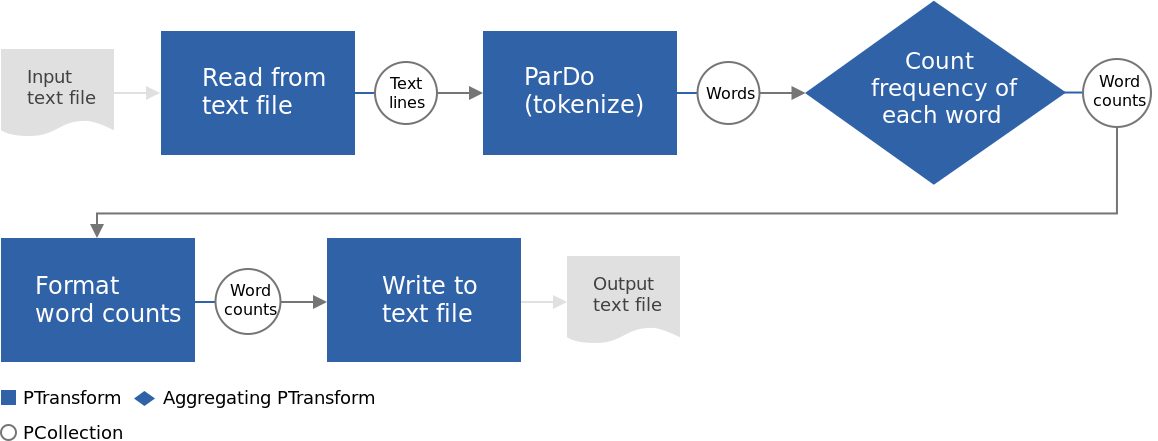
PCollection
A PCollection is an unordered bag of elements. It represents the data in our pipeline. PCollection can be either bounded or unbounded, depending on the nature of the data, as we mentioned earlier.
PCollection has several characteristics:
The elements in PCollection may be of any type, but all must be of the same type.
Once created, individual elements in a PCollection can’t be added, removed, or changed; therefore, they are immutable. Random access to individual elements is not supported. Each element has an associated timestamp assigned by the source.
PTransform
A PTransform is the heart of the pipeline. It represents a data processing operation or a step in the pipeline. By applying PTransform, we actually design the look of our pipeline graph and apply user code that will be applied to each element of an input PCollection. Depending on the pipeline runner, many different workers across the cluster may execute your code in parallel, and it is precisely where Apache Beam shows its full potential.
There are common transform types:
Source transforms that reads data into your pipeline;
Outputting transforms that write data to the desired sink;
Core Beam transforms designed for processing and conversion of data such as ParDo, GroupByKey, CoGroupByKey, Combine, and Count;
User-defined, application-specific transforms.
Please refer to their documentation to learn more about the Transform of Beam model.
Time domains
We can construct any pipeline that deals with bounded data by using just these three models. With unbounded data, there is another thing that we need to consider – time. When dealing with streaming data, we can observe incoming data in two-time domains: event time and processing time.
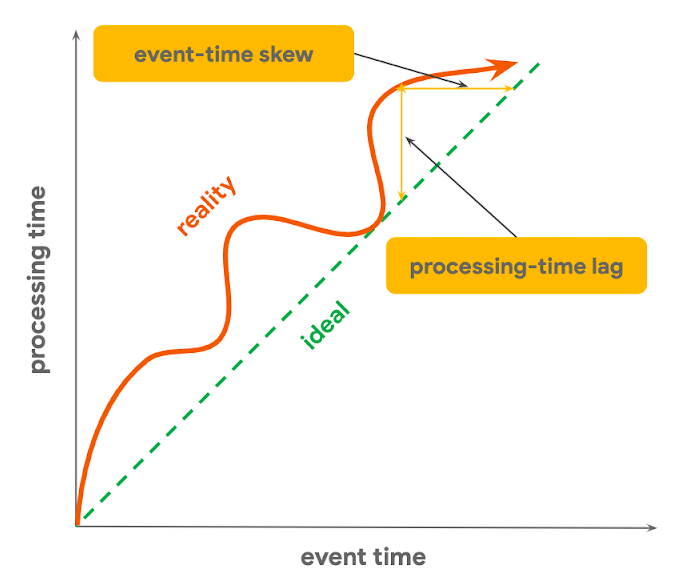
Event time is the time when a data event occurs. On the other hand, the processing time is the time when a data element gets processed at any stage in a pipeline. As we can see from the previous figure, in reality, there is always a lag between these two.
To understand better the difference, we can take a look at the following example:
| Time | Star Wars Episodes | ||||||||
| Processing | Episode IV | Episode V | Episode VI | Episode I | Episode II | Episode III | Episode VII | Episode VIII | Episode IX |
| Event | Episode I | Episode II | Episode III | Episode IV | Episode V | Episode VI | Episode VII | Episode VII | Episode IX |
For those who are not familiar with the Star Wars saga, the processing time here represents the order in which the movies were released, while the event time represents the order of the episodes in the chronology of the story.
To learn more about the properties of unbounded data and difficulties that may occur, you can check Streaming 101 & Streaming 102 by Tyler Akidau.
Now that we know that, let’s introduce three more concepts that Beam provides us with to deal with streaming data.
Window
A window subdivides a PCollection according to the timestamps of its individual elements, which is especially useful for unbounded PCollections, as it allows operating on sub-groups of elements. Each element is assigned to one or more widows according to the windowing function, and each window contains a finite number of elements. All grouping transforms in the Beam model work per-widow basis.
The Beam model provides several windowing functions:
Single global window – in this case, all data in a PCollection is assigned to the single global window, and late data is discarded.
Fixed time windows – represent a consistent duration, non-overlapping time interval in the data stream.
Sliding time windows – represent time intervals in the data stream; however, sliding time windows can overlap. The frequency with which sliding windows begin is called the period.
Per-session windows – defines windows that contain elements that are within a certain gap duration of another element. Session windowing applies on a per-key basis and is useful for data that is irregularly distributed with respect to time.
Watermark
A watermark is a heuristic function that tries to guess when all data in a certain window is expected to have arrived. Since it is based on heuristics, there is a possibility that some elements won’t fit this function. Once the watermark progresses past the end of a window, any additional element arriving with a timestamp in that window is considered late data. The default configuration doesn’t allow any late data; to handle those, we need to introduce triggers.
Trigger
A trigger determines when to emit the aggregated results of each window. Triggers allow Beam to emit early results if needed, for example, after a certain number of elements arrive or after a certain amount of time elapses. Triggers also allow the processing of late data.
The Beam provides some pre-built triggers that you can set:
Event time triggers – these triggers operate on event time
Processing time triggers – these triggers operate on the processing time
Data-driven triggers – these triggers fire when data meets a certain property
Composite triggers – combine multiple triggers mentioned above
To learn more about these concepts, you should definitely read the Beam documentation.
Summary: Why Use Apache Beam For Data Processing?
Apache Beam is a powerful and flexible tool for building large-scale data processing pipelines. Its unified programming model allows developers to write data processing logic that can run on multiple distributed processing platforms without worrying about the underlying implementation details. The kind of flexibility that comes with Apache Beam goes with a larger cost with regards to the use of processing power and memory. I believe that the Beam community is trying to make this overhead as small as possible, but the chances are that it will never be zero.

Bojan Ćorić
Sofware DeveloperBojan is a backend software developer at ProductDock, specializing in Java and Spring. He has been actively involved in developing robust and scalable backend systems for the past two years. His expertise in these technologies and his dedication to continuous learning make him a valuable asset in the field of software development.
Related posts.

Backend, Cloud
How to use MuleSoft for efficient CSV data streaming
Saša Jovanović• 17. Jul 2025
Find out more

Backend
Tailoring Keycloak: How to customise the authentication flow
Nina Romanić• 16. May 2025
Find out more