 DE
DE- AI acceleration
- Industries
- Finance
Nearshore software development for finance—secure, scalable, and compliant solutions for banking, payments, and APIs.
- Retail
Retail software development services—e-commerce, POS, logistics, and AI-driven personalization from nearshore engineering teams.
- Manufacturing
Nearshore manufacturing software development—ERP systems, IoT platforms, and automation tools to optimize industrial operations.
- Finance
- What we do
- Services
- Software modernization services
- Cloud solutions
- AI – Artificial intelligence
- Idea validation & Product development services
- Digital solutions
- Integration for digital ecosystems
- A11y – Accessibility
- QA – Test development
- Technologies
- Front-end
- Back-end
- DevOps & CI/CD
- Cloud
- Mobile
- Collaboration models
- Collaboration models
Explore collaboration models customized to your specific needs: Complete nearshoring teams, Local heroes from partners with the nearshoring team, or Mixed tech teams with partners.
- Way of work
Through close collaboration with your business, we create customized solutions aligned with your specific requirements, resulting in sustainable outcomes.
- Collaboration models
- Services
- About Us
- Who we are
We are a full-service nearshoring provider for digital software products, uniquely positioned as a high-quality partner with native-speaking local experts, perfectly aligned with your business needs.
- Meet our team
ProductDock’s experienced team proficient in modern technologies and tools, boasts 15 years of successful projects, collaborating with prominent companies.
- Why nearshoring
Elevate your business efficiently with our premium full-service software development services that blend nearshore and local expertise to support you throughout your digital product journey.
- Who we are
- Our work
- Career
- Life at ProductDock
We’re all about fostering teamwork, creativity, and empowerment within our team of over 120 incredibly talented experts in modern technologies.
- Open positions
Do you enjoy working on exciting projects and feel rewarded when those efforts are successful? If so, we’d like you to join our team.
- Hiring guide
How we choose our crew members? We think of you as a member of our crew. We are happy to share our process with you!
- Rookie boot camp internship
Start your IT journey with Rookie boot camp, our paid internship program where students and graduates build skills, gain confidence, and get real-world experience.
- Life at ProductDock
- Newsroom
- News
Stay engaged with our most recent updates and releases, ensuring you are always up-to-date with the latest developments in the dynamic world of ProductDock.
- Events
Expand your expertise through networking with like-minded individuals and engaging in knowledge-sharing sessions at our upcoming events.
- News
- Blog
- Get in touch

14. May 2026 •3 minutes read
Azure AI search deep dive: From SQL queries to AI-powered retrieval
Nemanja Marić
Software Engineer
This article is the first part of the Search Trilogy, a series comparing three major enterprise search platforms: Azure AI Search, Apache Solr, and Elasticsearch.
In this installment, we focus on Azure AI Search, Microsoft’s fully managed search service that combines traditional inverted-index search with AI enrichment and vector-based retrieval.
Limitations of traditional SQL search
SQL-based search is fundamentally limited to exact or pattern-based matching. It lacks:
- Relevance ranking based on scoring models
- Linguistic processing (stemming, synonyms)
- Autocomplete and suggestion capabilities
- Semantic understanding of queries
As a result, SQL queries return correct results but not necessarily relevant ones, especially for large or unstructured datasets.

Azure AI search architecture overview
Azure AI Search introduces a decoupled architecture where search is performed on a precomputed index rather than directly on the data source.
The system acts as an intermediary between:
- External data stores (unindexed raw data)
- Client applications (query execution and result consumption)
This separation enables optimized query performance, advanced ranking, and AI-driven enrichment.
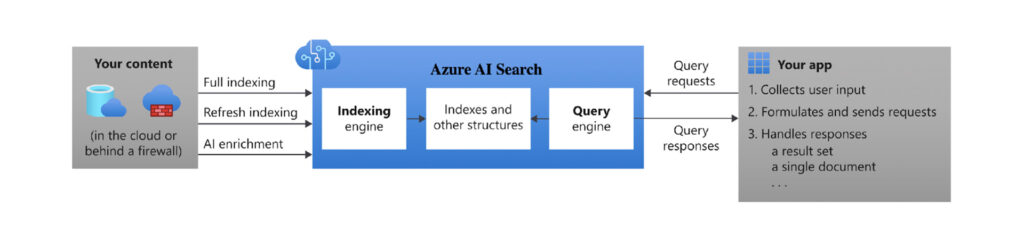
Core components
Data source
Data source defines the origin of the data (Azure SQL, Blob Storage, Cosmos DB, etc.).Important: Azure AI Search does not query the data source at runtime—all queries are executed against the index.
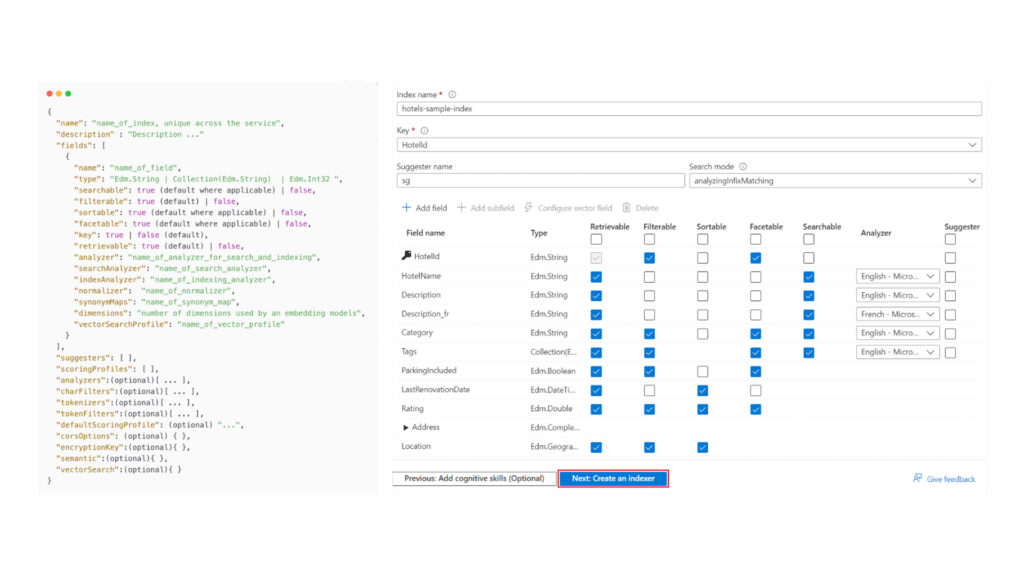
Index
The central data structure is similar to a search-optimized schema.
Each index:
- Has a defined schema
- Contains fields with attributes such as:
- searchable
- filterable
- sortable
- facetable
- retrievable
Proper field configuration is critical for query performance and flexibility.
Document
Represents the atomic unit of search.
- Equivalent to a JSON object
- Contains fields defined in the index schema
- Must include a unique key
Documents are ingested into the index via push or pull mechanisms.
{
"productId": "p001",
"name": "Wireless Bluetooth Headphones",
"description": "High-quality noise-cancelling headphones with long battery life.",
"price": 199.99,
"category": ["Audio", "Headphones"],
"rating": 4.5
}Indexer (pull model)
A scheduled crawler that:
- Extracts data from the data source
- Maps fields to the index schema
- Populates the index
Each indexer maintains a 1:1 relationship with a data source and index.
Push model (custom ingestion)
Data is explicitly pushed to the index via:
- REST API
- SDKs (Java, Python, C#, etc.)
This approach allows integration with non-Azure data sources or custom pipelines.
{
"name": "(required) String that uniquely identifies the indexer",
"description": "(optional)",
"dataSourceName": "(required) String indicating which existing data source to use",
"targetIndexName": "(required) String indicating which existing index to use",
"parameters": {
"batchSize": null,
"maxFailedItems": 0,
"maxFailedItemsPerBatch": 0,
"base64EncodeKeys": false,
"configuration": {}
},
"fieldMappings": "(optional) unless field discrepancies need resolution",
"disabled": null,
"schedule": null,
"encryptionKey": null
}Skillsets (AI enrichment pipeline)
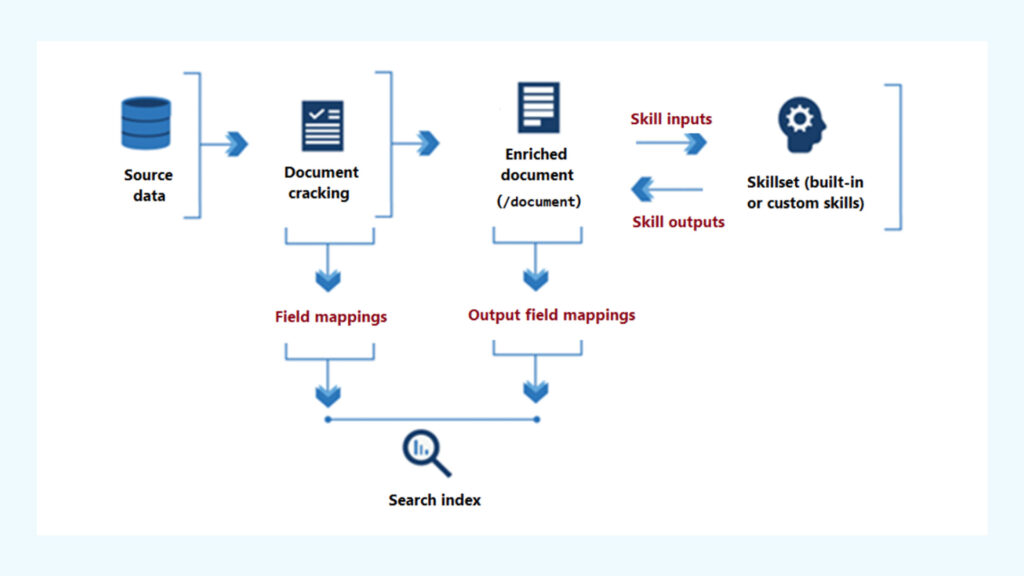
Skillsets define a pipeline of cognitive transformations applied during indexing.
Common capabilities:
- OCR for text extraction from images/PDFs
- Language detection and translation
- Key phrase extraction
- Entity recognition
Skillsets operate before data is indexed, enriching documents with additional searchable metadata.
Query layer
Azure AI Search supports multiple query paradigms:
- Full-text search (Lucene-based, fuzzy, autocomplete)
- Vector search (embedding-based similarity search)
- Hybrid search (combining lexical + vector queries)
Query execution includes:
- Scoring and ranking
- Filtering ($filter)
- Sorting ($orderby)
- Faceting
{
"method": "POST",
"url": "/indexes/products/docs/search?api-version=2023-07-01",
"body": {
"search": "wireless headphones",
"filter": "brand eq 'Sony'",
"top": 5
}
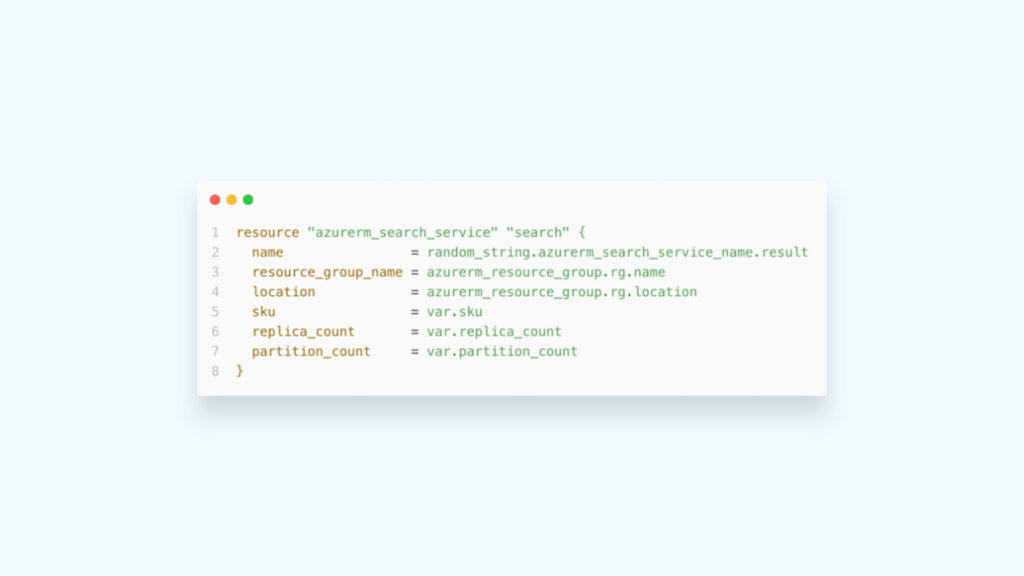
}Infrastructure as code considerations
Azure AI Search has partial Terraform support:
Supported:
azurerm_search_service (search service provisioning)
Not supported:
- Indexes
- Indexers
- Skillsets
These must be created via:
- REST API
- Azure SDKs
This introduces a hybrid provisioning model in which IaC handles infrastructure, while application-level configuration is API-driven.
resource "azurerm_search_service" "example" {
name = "my-search-service"
resource_group_name = "rg-example"
location = "West Europe"
sku = "standard"
}Retrieval-augmented generation (RAG)
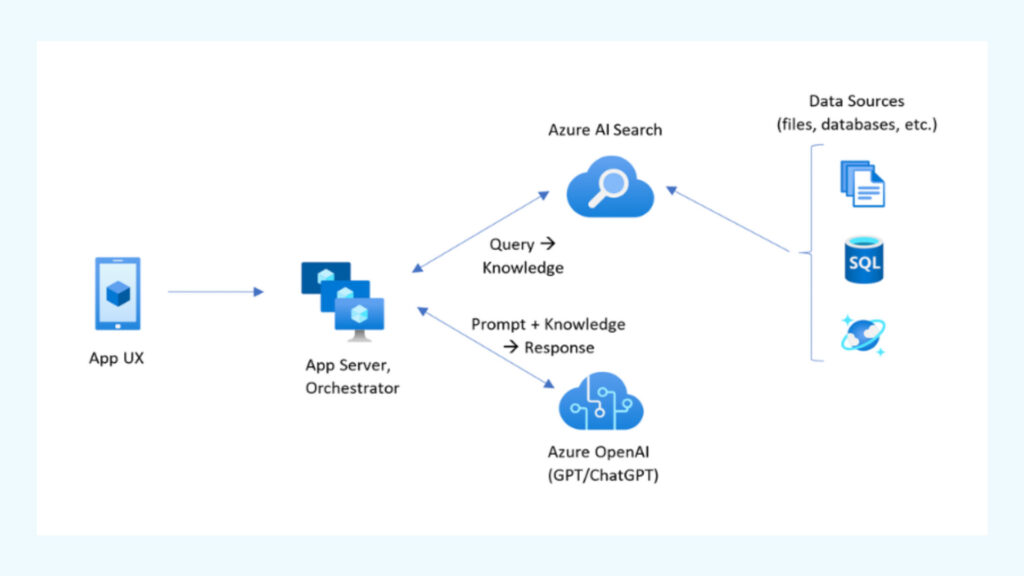
Azure AI Search integrates directly into RAG architectures.
Typical flow:
- User submits a natural language query
- Search service retrieves relevant documents (keyword, vector, or hybrid)
- Results are passed to an LLM (e.g., Azure OpenAI)
- The model generates a grounded response
This approach improves:
- Accuracy
- Context awareness
- Explainability of AI outputs
Practical use cases
Azure AI Search is particularly effective in scenarios involving:
- Large-scale document search (PDFs, knowledge bases)
- E-commerce product discovery (faceted filtering, ranking)
- AI assistants with contextual retrieval
- Enterprise search across heterogeneous data sources
Conclusion
Azure AI Search provides a search-first architecture that separates data storage from retrieval, enabling scalable, performant, and intelligent search experiences.
Key strengths:
- Precomputed indexing for performance
- AI enrichment for unstructured data
- Hybrid search (lexical + vector)
- Integration with generative AI (RAG)
In the next part of the Search Trilogy, we will analyze Apache Solr, focusing on its flexibility, configuration model, and on-premise capabilities.
Tags:Skip tags

Nemanja Marić
Software EngineerNemanja Marić is a software engineer with 6 years of hands-on experience in building robust and scalable applications. He holds a BSc in Software Engineering and specializes primarily in Java and Spring. Along the way, he had also explored C#, React, Cloud Computing, and Flutter. He approaches software development with genuine joy and a passion for creating impactful solutions by building scalable, robust, and high-quality software.
Related posts.

AI
Apache Solr deep dive: From full-text search to distributed search architecture
Nemanja Marić• 02. Jul 2026
Find out more
AI
AI in retail (part 1): Better experiences, but bigger risks
Marta Costa• 16. Jun 2026
Find out more